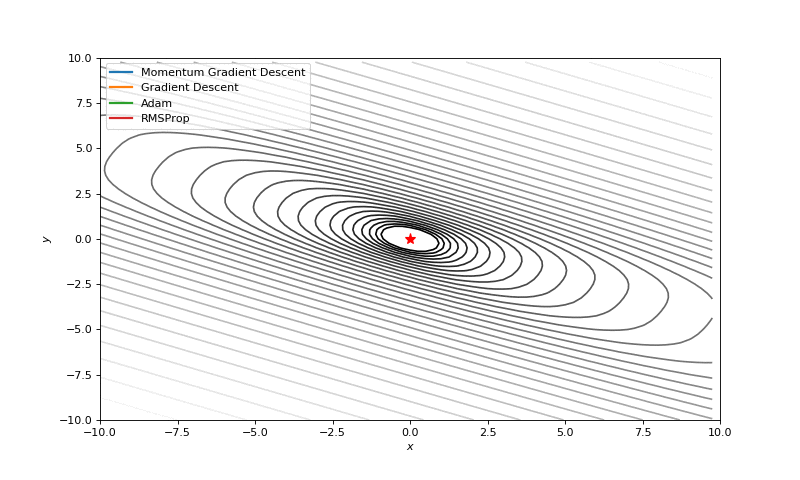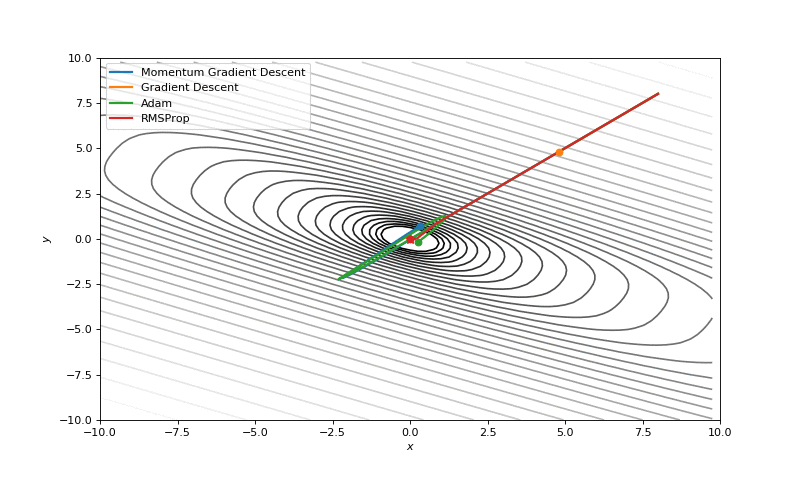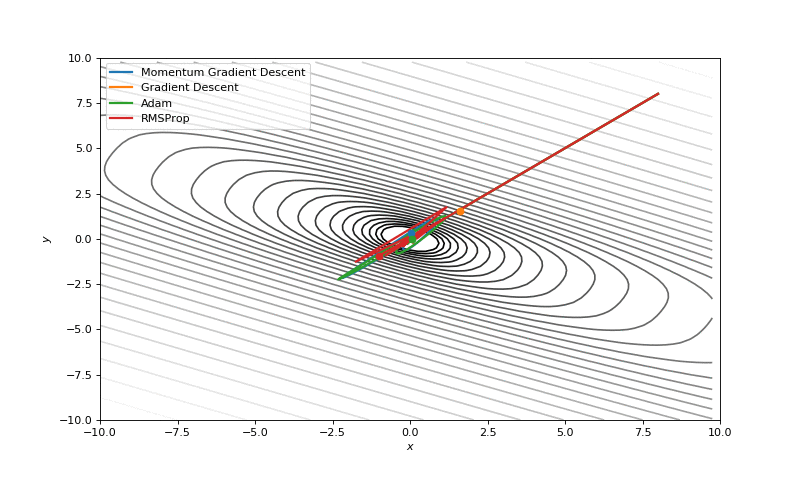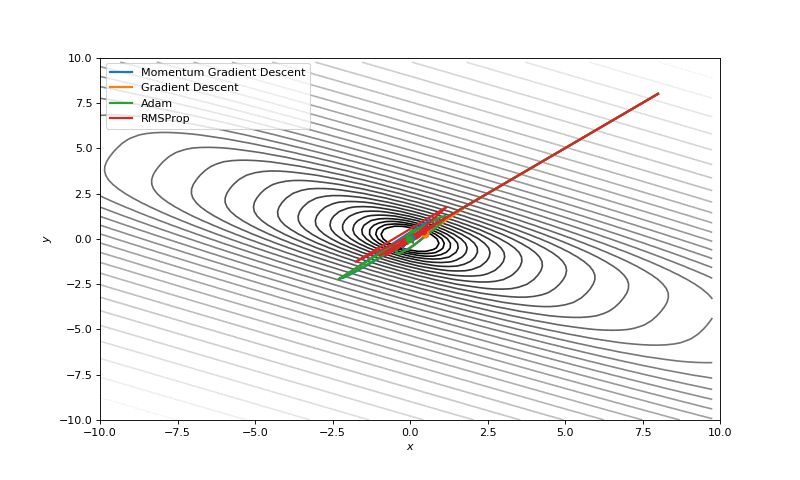
Básicamente el algoritmo toma la derivada de la función en cuestión, pues ésta mide la rapidez con que cambia la función, esto es, cuando crece o decrece. Calculando la pendiente en un punto en específico, sabremos en ese punto cuando la función crece, de modo que podemos seguir la dirección contraria a la pendiente obtenida e iremos bajando hasta un punto mínimo.
EL gradiente de una función $f$ es la generalización vectorial de la derivada, siendo éste un vector que contiene la información de cuando crece la función en un punto en específico $x=(x_{1},\ldots,x_{n})$, donde:
$$
\nabla f=\left[\frac{\partial f}{\partial x_{1}},\ldots, \frac{\partial f}{\partial x_{n}}\right]
$$