Curso PostgreSQL¶
 Autor: Luis Fernando Apáez Álvarez
Autor: Luis Fernando Apáez Álvarez
-Curso PyM-
Proyecto 1: Diseño de bases de datos
Fecha: Abril del 2023
Autor: Luis Fernando Apáez Álvarez
-Curso PyM-
Proyecto 1: Diseño de bases de datos
Fecha: Abril del 2023
En este proyecto realizaremos la implementación desde cero de una base de datos en PostgreSQL, partiendo desde su correcto diseño, hasta la propia implementación de código. Para ello, supondremos que se nos ha contratado para diseñar una base de datos funcional para un sistema bibliotecario en una escuela primaria.
El primer paso para el diseño de una base de datos corresponde a:
Preguntemos a ChatGPT:
Qué es un análisis de requerimientos en un contexto de bases de datosRespuesta
En un contexto de bases de datos, el análisis de requerimientos se refiere al proceso de identificar, comprender y documentar las necesidades y requisitos de los usuarios y partes interesadas para el diseño y desarrollo de una base de datos.
El análisis de requerimientos en este contexto implica la identificación de los tipos de datos que se necesitan almacenar, cómo se relacionan entre sí, qué reglas de validación deben aplicarse, qué consultas deben ser posibles, cómo se realizarán las operaciones de entrada y salida de datos, entre otros aspectos relevantes para el correcto funcionamiento de la base de datos.
El análisis de requerimientos en una base de datos puede incluir entrevistas con los usuarios y partes interesadas, revisión de documentación existente, prototipado de la base de datos y pruebas de usuario para garantizar que los requisitos se hayan comprendido correctamente y que la base de datos funcione de manera efectiva. Una vez que se han identificado y documentado los requerimientos, se pueden utilizar como base para el diseño y la implementación de la base de datos.Así, supongamos que nos reunimos con el encargado de la biblioteca de la primaria y nos dice, en resumen, que
Con base en el análisis de requerimientos, tenemos las siguientes tablas candidatas:
Inventario: almacenará la información de todos los libros de la biblioteca, como nombre, tema, número de ejemplares, código de ubicación del estante.Usuarios: información de los alumnos registrados en el sistema de la biblioteca.Prestamos: Información de préstamo de cada libro. Tendrá el nombre del alumno que pidió el libro, nombre del libro, fecha de pedido y fecha de entrega, tendrá una columna de estatus referente a si el alumno entregó en tiempo o no.Una vez que tenemos las tablas cantidatas:
En este punto definiremos las columnas de cada tabla, así como el tipo de dato para las mismas y las relaciones entre las tablas. Para ello:
ID_libro: será una columna que sirva como identificador único de cada libro. Será un número entero. Será la llave primaria de esta tabla.nombre_libro: nombre de cada libro. Será una cadena de texto.Sección: será la sección a la que pertenece cada libro, como Matemáticas, Historia, etc. Será una cadena de textoNum_ejemplares: total de copias de un mismo libro disponible en la biblioteca. Será un número entero.Codigo_ubi: será un código único de ubicación del libro en los estantes, por ejemplo, QA351, QA352, etc. Será una cadena de texto.Es importante mencionar que esta tabla estará conectada con las tablas: Prestamos y Estado_libros, de modo que tendremos que definir llaves foráneas en dichas tablas a partir de la llave primaria de esta tabla (Inventario).
Información anterior resumida:
| Columna | Tipo de dato | Restricción | |
|---|---|---|---|
| ID_libro | SERIAL | PK | |
| nombre_libro | VARCHAR | ||
| sección | VARCHAR | ||
| Num_ejemplares | INTEGER | ||
| Codigo_ubi | VARCHAR |
ID_alumno: Nombre_alumno:Fecha_registro:Fecha_vigencia:Ciclo_escolar: ID_prestamos:ID_alumno_prestamos: Tendrá el id del alumno que previamente está registrado en el sistema de la biblioteca. Será un entero y además es llave foránea que referencia la llave primaria ID_alumno de la tabla Usuarios.ID_libro_prestamos:Fecha_pedido:Fecha_entrega:Estatus: Será un valor booleano. Si consideramos el valor True, entonces significa que el estado del préstamo es correcto, es decir, o que el alumno entrego en tiempo y forma o que el libro sigue en préstamo. False indicará que el alumno no ha entregado el libro después de la fecha de entrega.Pero, ¿qué es un diagrama relacional? Según chatGPT:
Un diagrama relacional es una representación visual de las relaciones entre las tablas de una base de datos relacional. En él, se muestran las tablas y las relaciones entre ellas mediante líneas que unen las columnas que se relacionan.
El diagrama relacional es una herramienta importante en el diseño de bases de datos porque ayuda a los diseñadores a visualizar cómo se relacionan los datos y a asegurarse de que se establezcan las relaciones adecuadas entre las tablas. Además, el diagrama relacional facilita la comunicación entre los diseñadores de la base de datos y otros miembros del equipo de desarrollo.
En un diagrama relacional, cada tabla se representa mediante un rectángulo que contiene el nombre de la tabla y sus columnas. Las relaciones entre las tablas se representan mediante líneas que conectan las columnas que tienen la misma información. Por ejemplo, en un diagrama de ventas, la tabla de pedidos estaría conectada con la tabla de clientes mediante una línea que uniera la columna de "cliente_id" de la tabla de pedidos con la columna de "id_cliente" de la tabla de clientes.
En resumen, un diagrama relacional es una herramienta visual que representa las relaciones entre las tablas de una base de datos relacional, lo que ayuda en el diseño y la comunicación de la estructura de la base de datos.Ejemplo de diagrama relacional:
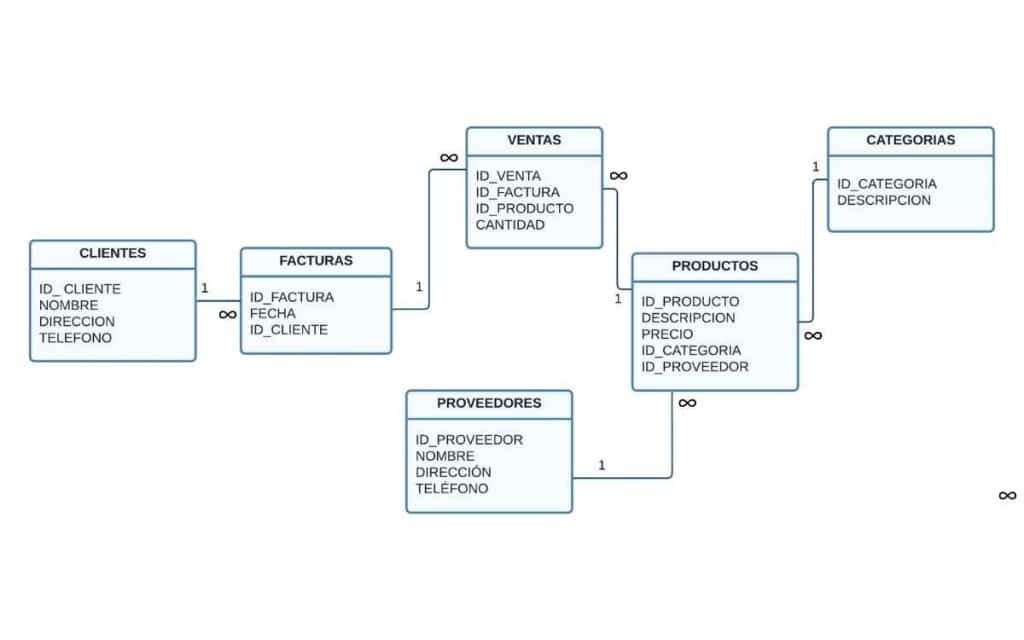
En nuestro caso, adicionalmente deberás mostrar el tipo de dato y si una columna es llave primaria o foránea.
Por otro lado, debido a que el ejemplo que estamos trabajando aún es un poco sencillo, en este caso no será necesario realizar pruebas para verificar si el diseño y la base de datos satisface todas las necesidades del cliente. No obstante, un buen ejercicio sería que analizarás hasta ahora la estructura de la base de datos y te preguntarás:
Donde las preguntas anteriores funcionan como un bucle, es decir, si modificamos la base de datos, debemos preguntarnos todo de nuevo, y así sucesivamente hasta que estemos satisfechos con los resultados (y bueno, satisfechos también de las pruebas realizadas en caso de hacerlas). En las pruebas se suele simular el funcionamiento de la base de datos con información que nos ayude a, justamamente, probarla y ver qué podemos cambiar o si la base de datos ya funciona bien.
Una vez que ya hemos diseñado la base de datos, lo que sigue es implementar el correspondiente código SQL para definirla. Así, tenemos que para la tabla Inventario que describimos como
ID_libro: será una columna que sirva como identificador único de cada libro. Será un número entero. Será la llave primaria de esta tabla.nombre_libro: nombre de cada libro. Será una cadena de texto.Sección: será la sección a la que pertenece cada libro, como Matemáticas, Historia, etc. Será una cadena de textoNum_ejemplares: total de copias de un mismo libro disponible en la biblioteca. Será un número entero.Codigo_ubi: será un código único de ubicación del libro en los estantes, por ejemplo, QA351, QA352, etc. Será una cadena de texto.el correspondiente código SQL en postgres queda como
-- Primero creamos la base de datos
CREATE DATABASE Proyecto1;
-- Creamos la tabla
CREATE TABLE Inventario(
ID_libro SERIAL,
Nombre_libro VARCHAR,
Seccion VARCHAR,
Num_ejemplares INT,
Codigo_ubi VARCHAR
)
Una vez que ya tenemos la información completa en la base de datos, lo que haremos será jugar con las consultas. Recuerda que las instrucciones que vimos en clase fueron:
Asimismo, vimos cómo modificar nuestros datos valiéndonos de la sentencia ALTER TABLE, UPDATE Y DELETE (Sección B).
Con base en todo lo anterior:
Ejercicio a): Realiza 10 consultas donde utilices las sentencias en la **sección A**Ejercicio b): Realiza modificaciones a la base de datos, para ello deberás utilizar las sentencias de la **sección b**.